Intro to Langchain
LangChain is a framework for developing applications powered by language models. LangChain uses providers to connect to existing models such as OpenAI’s GPT, Anthropic’s Claude among others. Community providers also exist, allowing integration with AWS Bedrock and Azure OpenAI.
In this article, we will create a simple chatbot using LangChain. We will cover topics such as:
- What is a Chain? (prompt -> model -> output parser)
- Retrieval Augmented Generation (RAG)
- Using
ChatMessageHistoryto allow our bot to “remember” - LangChain Hub
If you’d like to follow along, please obtain an OpenAI API Key from OpenAI.
Preface
- Token ≈ 4 characters. On average, a token is about 4 characters. 100 tokens is about 75 words.
- Temperature: The temperature value ranges from 0 to 1, with lower values indicating greater determinism and higher values indicating more randomness in generated responses.
- Top-k sampling: Samples tokens with the highest probabilities until the specified number of tokens is reached.
- Top-p sampling: Samples tokens with the highest probability scores until the sum of the scores reaches the specified threshold value. (Top-p sampling is also called nucleus sampling. 0 <= top-p <= 1.0)
- Context Window: LLMs have limits on how many tokens we can pass to them — we call this limit the context window.
Tokens
In the context of Natural Language Processing (NLP), tokens are the smallest units of text that are meaningful to the language. They can be words, characters, or subwords, depending on the level of analysis. Here are some examples of tokens in NLP:
- Words
Example: “The quick brown fox jumps over the lazy dog.” Tokens: “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”.
- Characters
Example: “Hello, world!” Tokens: “H”, “e”, “l”, “l”, “o”, ”,”, ” ”, “w”, “o”, “r”, “l”, “d”, ”!”.
- Subwords
Example: “unhappiness” Tokens: “un”, “happiness”, “ness”.
- Phrases
Example: “The quick brown fox jumps over the lazy dog.” Tokens: “The quick brown fox”, “jumps over the lazy dog”.
- Sentences
Example: “The quick brown fox jumps over the lazy dog. The dog is happy.” Tokens: “The quick brown fox jumps over the lazy dog.”, “The dog is happy.”
- N-grams
Example: “The quick brown fox jumps over the lazy dog.” Tokens (2-grams): “The quick”, “quick brown”, “brown fox”, “fox jumps”, “jumps over”, “over the”, “the lazy”, “lazy dog”.
Context Window
As of this writing, Anthropic’s Claude v2.1 model supports 200,000 tokens of context (about 150,000 words, or 500 pages of text).
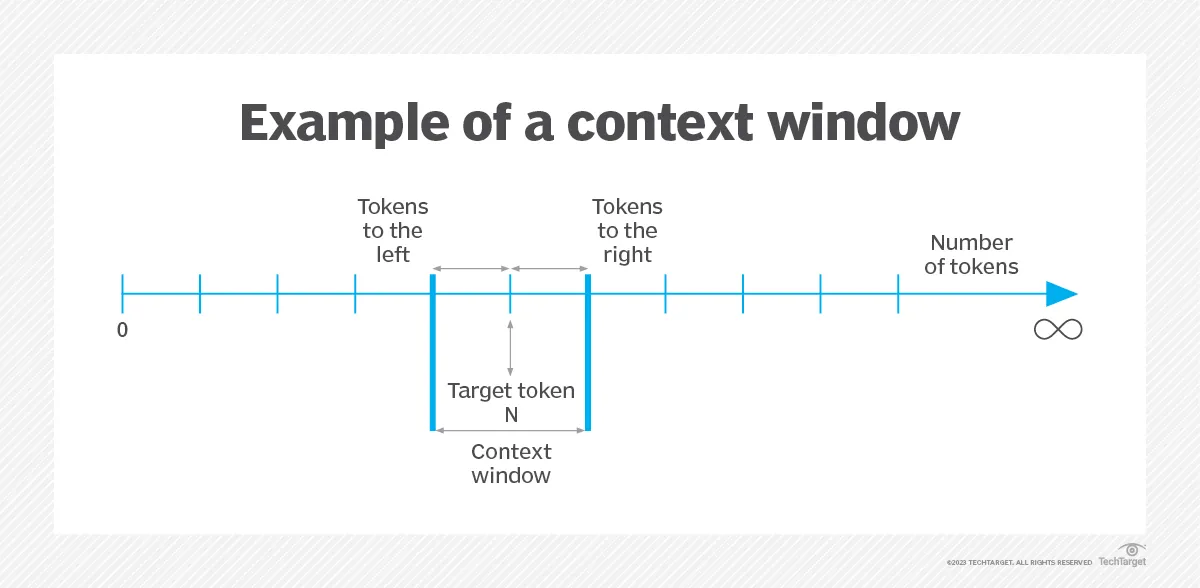
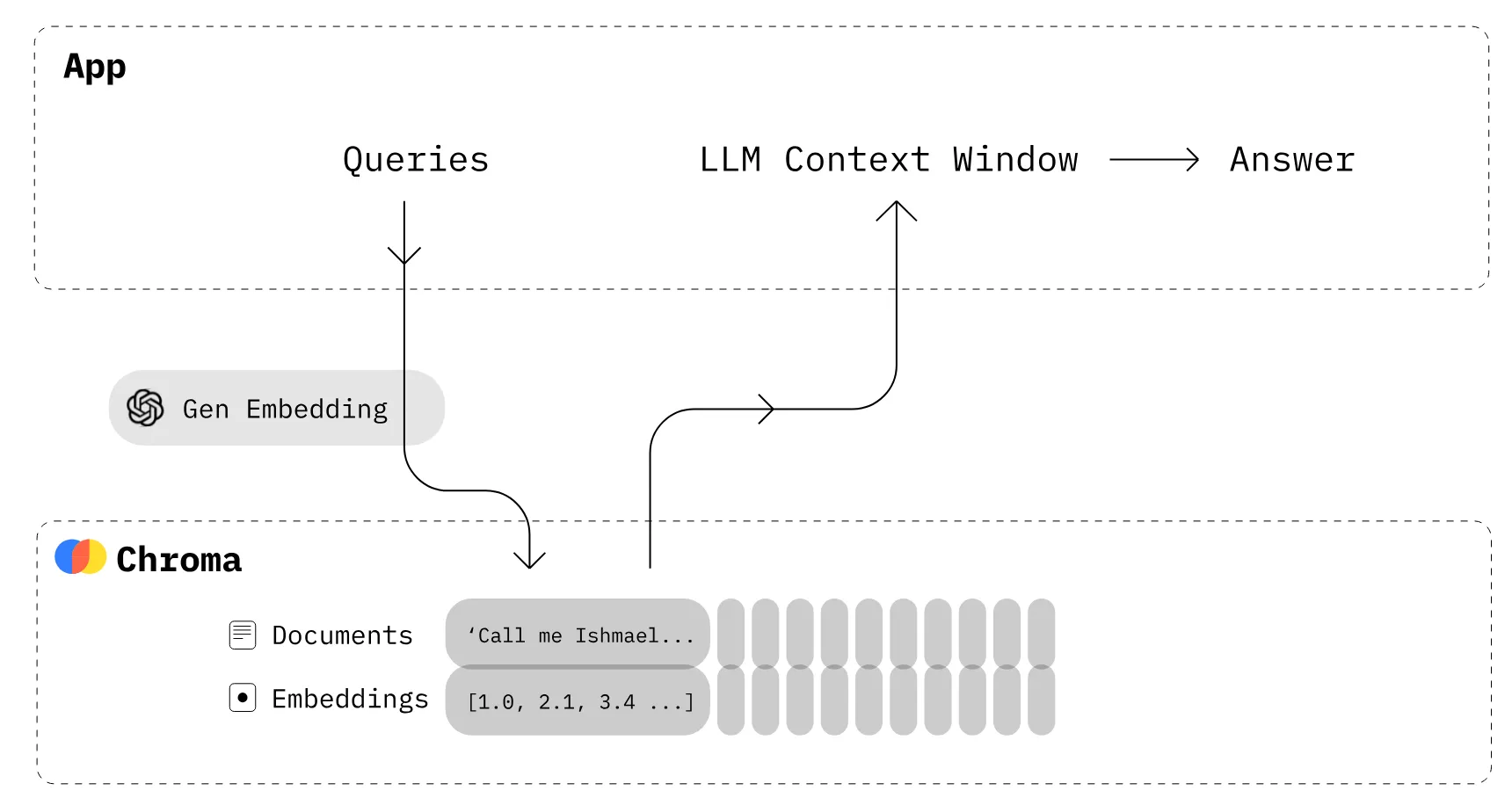
A query is used along with relevant data from RAG or a Vector Database, which is loaded into the Context Window. A larger Context Window allows for an LLM to process bigger text documents, but it can also cause the LLM to “hallucinate”.
Simple Chain
Prompt Template → Chat Model → Output Parser
https://python.langchain.com/docs/expression_language/get_started
from dotenv import load_dotenv
load_dotenv() # load OPENAI_API_KEY from .env
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
output_parser = StrOutputParser()
chain = prompt | model | output_parser
# Zero Shot Prompting
chain.invoke({"topic": "ice cream"})Output
'Why did the ice cream go to therapy? Because it had too many sprinkles of anxiety!'1) Prompt
Zero Shot Prompting
prompt is a BasePromptTemplate, which means it takes in a dictionary of template variables and produces a PromptValue. A PromptValue is a wrapper around a completed prompt that can be passed to either an LLM (which takes a string as input) or ChatModel (which takes a sequence of messages as input). It can work with either language model type because it defines logic both for producing BaseMessages and for producing a string.
https://python.langchain.com/docs/expression_language/interface
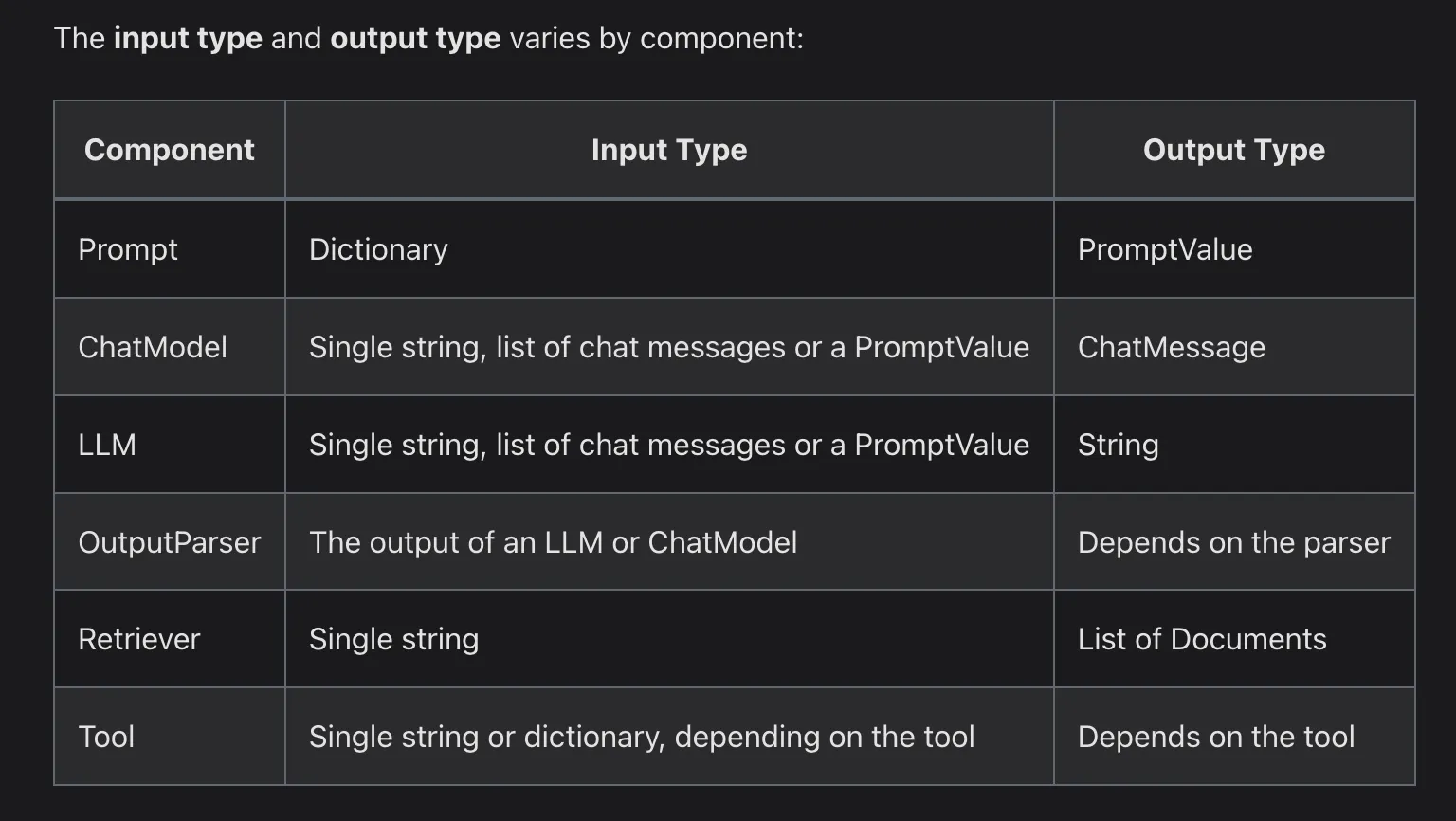
The Runnable protocol is implemented for most components. This is a standard interface, which makes it easy to define custom chains as well as invoke them in a standard way (i.e. via invoke).
prompt_value = prompt.invoke({"topic": "ice cream"})
prompt_value
# Output:
# ChatPromptValue(messages=[HumanMessage(content='tell me a short joke about ice cream')])
prompt_value.to_messages()
# Output:
# [HumanMessage(content='tell me a short joke about ice cream')]
prompt_value.to_string()
# Output
# 'Human: tell me a short joke about ice cream'Few Shot Prompting
from langchain_core.prompts import ChatPromptTemplate
# Few Shot Prompting
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
model.invoke(input=messages)
# Output:
# AIMessage(content='My name is Bob. How can I assist you today?', response_metadata={'finish_reason': 'stop', 'logprobs': None})2) Model
response = model.invoke(prompt_value)
response
# Output:
# AIMessage(content='Why did the ice cream truck break down? It had too many "scoops"!', response_metadata={'finish_reason': 'stop', 'logprobs': None})If our model was an LLM (instead of a Chat Model), it would output a string.
from langchain_openai.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct")
llm.invoke(prompt_value)
# output:
# '\n\nRobot: Why did the ice cream truck break down? Because it had a meltdown!'3) Output Parser
And lastly we pass our model output to the output_parser, which is a BaseOutputParser meaning it takes either a string or a BaseMessage as input. The StrOutputParser specifically simple converts any input into a string.
output_parser.invoke(response)
# Output:
# Why did the ice cream truck break down? It had too many "scoops"!We can also inspect the output at each stage of the chain:
input_topic = {"topic": "ice cream"}
prompt.invoke(input_topic)
# > ChatPromptValue(messages=[HumanMessage(content='tell me a short joke about ice cream')])
(prompt | model).invoke(input_topic)
# > AIMessage(content="Why did the ice cream go to therapy?\nBecause it had too many toppings and couldn't cone-trol itself!")Simple Chatbot
Reference: https://python.langchain.com/docs/use_cases/chatbots/quickstart
With ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=1.0)
output_parser = StrOutputParser()
chain = prompt | model | output_parser
while True:
topic = input("> ")
if topic == "exit":
break
response = chain.invoke({"topic": topic})
print(response)
# Output:
# > python
# Why was the python programmer unhappy? Because he didn't get a byte!
# > LLMs
# Why did the LLM go to law school? To become an MA (Master of Arguments)!
# > exitI never said these jokes would be good :b
Without ChatPromptTemplate
Without a prompt template, we have more freedom over how we interact with the chatbot. This allows for a more free-form conversation.
from langchain_core.output_parsers import StrOutputParser
# from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)
output_parser = StrOutputParser()
chain = model | output_parser
while True:
prompt = input("> ")
if prompt == "exit":
break
response = chain.invoke(prompt)
print(response)
# Output:
# > hello
# Hello! How can I assist you today?
# > what is 6 divided by 4?
# 6 divided by 4 equals 1.5.
# > what did I just ask you?
# You asked me, "what did I just ask you?"
# > exitHowever, there is a problem. The chat model has no memory of our conversation history. We can fix that by storing our prompt message as well as the response in a list. We can then pass this list to the model along with our prompt.
With Message History
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_openai import ChatOpenAI
# prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.5)
output_parser = StrOutputParser()
chain = model | output_parser
# Message for priming AI behavior, usually passed in as the first of a sequence of input messages.
system_message = SystemMessage(content="You are a friendly chatbot assisant. You SHOULD help the user to the best of your abilities. If you are unable to answer a question, or you don't understand the user's input, you MUST tell a joke instead.")
messages = [system_message]
while True:
prompt = input("> ")
if prompt == "exit":
break
human_message = HumanMessage(content=prompt)
messages.append(human_message)
response = chain.invoke(messages)
messages.append(response)
print(response)
# Output:
# > oasidfjo
# Why did the scarecrow win an award? Because he was outstanding in his field! How can I assist you today?
# > What is the capital of Canada?
# The capital of Canada is Ottawa. How can I help you with anything else today?
# > What did I just ask you?
# Hmm... I think you just asked me about the capital of Canada. Did I get that right? How else can I assist you today?
# > exitprint(messages)
# Output:
# [SystemMessage(content="You are a friendly chatbot assisant. You SHOULD help the user to the best of your abilities. If you are unable to answer a question, or you don't understand the user's input, you MUST tell a joke instead."), HumanMessage(content='oasidfjo'), AIMessage(content='Why did the scarecrow win an award? Because he was outstanding in his field! How can I assist you today?'), HumanMessage(content='What is the capital of Canada?'), AIMessage(content='The capital of Canada is Ottawa. How can I help you with anything else today?'), HumanMessage(content='What did I just ask you?'), AIMessage(content='Hmm... I think you just asked me about the capital of Canada. Did I get that right? How else can I assist you today?')]In the message history, we can see there are 3 types of messages
- SystemMessage - A message to prime the chat model, typically set at the beginning of the conversation
- HumanMessage - Our prompt string
- AIMessage - Response from the chat model
Retrieval Augmented Generation
# Load docs
# https://python.langchain.com/docs/modules/data_connection/document_loaders/
from langchain.document_loaders import WebBaseLoader
# Alice In Wonderland
url = "https://www.gutenberg.org/files/11/11-0.txt"
loader = WebBaseLoader(url)
data = loader.load()
# Split/Chunk
# https://js.langchain.com/docs/modules/data_connection/document_transformers/
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 20)
all_splits = text_splitter.split_documents(data)
print(all_splits)
# Store splits
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
# RAG prompt
from langchain import hub
prompt = hub.pull("tpulliam/rag-prompt")
# LLM
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": prompt}
)
question = "Who is the author?"
result = qa_chain.invoke({"query": question})
result["result"]
# Output:
# The author is Lewis Carroll.- We load a text file from a website. In this case we are loading Alice In Wonderland.
- We split the text into overlapping chunks of text objects called Documents and store these in a list. This is necessary to fit the text chunks into the Context Window and to facilitate searching the embedded text later.
- We embed each Document text into a vector representation of the semantic meaning of the text.
- We then store these vectors in a vector database. In this case ChromaDB
- We load our prompt. We are pulling the following prompt from Langchain Hub
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:- We create the model.
- Create and invoke the chain